

- Структурні дані
- Відносини фраз
- Близькі місця - в процесі підготовки
- Особливості контексту запиту
- Результати пошуку та натуральна мова

Ми поступово пробиваємося через густість факторів ранжування Google - сьогодні ми розглядаємо семантичні показники під мікроскопом. Семантичний пошук означає виходити за рамки простого розуміння слів або їх синонімів. Зв'язування слів і фраз з їх атрибутами, атрибутами або іншими фразами, з якими вони мають відношення, допомагає пошуковій системі краще інтерпретувати запити користувачів. Здається складним? Завдяки наведеним нижче прикладам, це буде просто приємніше!
У нашому циклі "Фактори ранжирування Google" ми описуємо тільки ті фактори, які підтверджені в зареєстрованому патенті Google, завдяки відмінному рейтингу Seo by the sea - Біла Славська ,
Структурні дані
друга частина Ми писали про наш цикл, що Google, використовуючи результати пошуку, використовує бази даних. Обговорюваний сьогодні патент показує, що він також використовує структурні дані, тобто впорядковані за схемою. Найпростішим способом зрозуміти це на прикладі книг - структурних даних є інформація про них у вигляді сценарію - рік видання книги, автора, літературної епохи або історичного періоду, в якому було створено положення літератури. Пошук структурованих даних здійснюється інакше, ніж фактичні фрази, що містяться в запиті. Це описується графіком патенту:
- Google отримує запит;
- Ідентифікує діаграми, що містять конкретні питання з запиту;
- У схемах він шукає відповідні структурні дані;
- Елементи даних перетворюють і, упорядковуючи за значенням, надають користувачеві його запит в результатах пошуку.
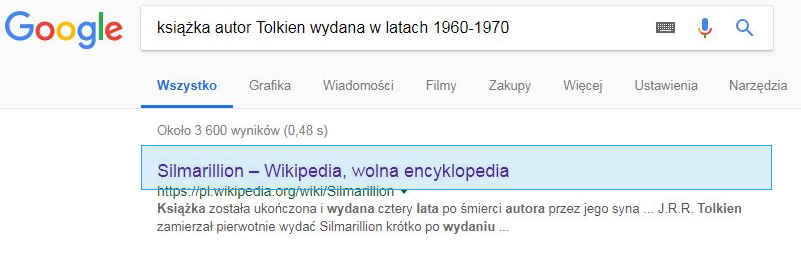
Завдяки цьому патенту Google здатний відповісти на запит "автор Толкієн, опублікований у 1960-1970 роках", вказуючи на правильний результат пошуку. Структуровані дані часто є основою для генерування Google Knowledge Graph - кадру з вмістом знань, який подає дані про фразу безпосередньо в результатах пошуку. Ми написали про Граф знань в одній з попередніх частин циклу при обговоренні фактора "котирування". Посилання на патент Google: Збір напівструктурованих даних
Рекомендації: Правильні дані повинні бути включені на веб-сайті таким чином, щоб пошукова система могла легко її обробляти. Вони мають форму сценарію, який можна вставити в код сторінки. Біл Славський рекомендує сайт Schema.org де можна дізнатися більше про сценарії, особливо про сценарій, який використовує Google JSON-LD ,
Відносини фраз
Якщо для кожної фрази відзначити всі її відносини з іншими фразами, то виявиться, що ми будуємо сайти, позиціонуючи вирази після найпоширеніших асоціацій. Немає нічого поганого в цьому, якби не той факт, що пошукова система Google також знає менш відомі особливості та зв'язки фраз. Він знає це на основі запитань користувачів та інформації на веб-сайтах. І якщо користувачі звертаються до цих менш відомих асоціацій, їх варто поставити! Приклад? Станіслав Виспьянський, який живе в епоху Молодої Польщі, є одним з найпопулярніших польських письменників і поетів. Однак пошуковик також знаходить - набагато рідше, але все ж - запити про його живопис, графічний дизайн і навіть «банкнота Станіслава Виспьянського». Ми знаємо, що його обличчя було на банкноті 10 000 злотих до 1996 року. Підсумовуючи, отже, менш відомі зв'язки фраз, про які ми пишемо в Інтернеті, також впливають на їхній показ у результатах пошуку. Посилання на патент Google: Результати пошуку на основі сортованих властивостей
Рекомендації: Якщо припустити, що 90% запитів Google щодо Станіслава Виспьянського стосуватимуться його літературного випуску - чи варто витрачати час і увагу на решту 10% запитів щодо малювання, графіки або банкнот? Так, тому що розміщення інформації у вигляді цікавості збагачує зміст і привертає увагу читачів. З точки зору SEO - теж. Біл Славський дає, наприклад, інформацію про те, що Джордж Вашингтон був залучений до геодезії, перш ніж стати президентом Сполучених Штатів. Якщо Google бачить взаємозв'язок між Г.Вашингтоном і геодезією, то запити щодо цих відносин не будуть відображати сторінки, присвячені виключно його політичної кар'єрі.
У перекладі на мову продукту - ми можемо шукати ці унікальні 10% асоціації та посилання, які збагатять вміст веб-сайтів. Важливо, однак, що це фрази, які з'являються в запитах клієнтів. Прикладом може бути сайт дієтолога і фраза «дієтолог як набирати вагу» або «дієтолог при хворобі Лайма», що є невеликим відсотком запитів серед переважної більшості цих типів: «дієтолог, як схуднути» або «як схуднути з дієтологом».
Близькі місця - в процесі підготовки
Місцезнаходження, розташування, розташування! Саме число факторів ранжирування Google, які впливають на неї, свідчить про її велику вагу. Ми вже писали про фізичну адресу на сайті, про географічні координати та місцеві запити. Сьогодні ми просуваємо інший патент: закрийте місця . Чим відрізнятиметься цей патент від прохання поштового поста? Справа в тому, що користувачеві не потрібно знати, що він шукає, але він повинен бути безпосередньо на ньому. Наприклад, Google планує надати відповідь на таке питання, як "Що таке пам'ятник" або "Який парк я". Google, що читає цей запит користувача, використовує своє місцезнаходження та фразу "пам'ятник", "парк", надаючи відповіді. Фактор ще не введений. Посилання на патент Google: Відповідайте на запити користувачів на основі близьких місць
Рекомендації: До введення патенту немає нічого іншого, окрім як прогулятися смартфоном і перевірити, чи функція вже працює. Великою перевагою після його впровадження стане той факт, що користувачеві не потрібно знати назву того, з чим він стикається, щоб він міг читати про нього в результатах пошуку.
Особливості контексту запиту
Можливості шуканої фрази можуть запропонувати запитання пошуковій системі, навіть якщо вона фактично не була введена користувачем у Google. Приклади? Ми часто набираємо в Google: "головний біль, нежить, кашель", і в результатах ми знаходимо відповідь на питання: "Я шукаю хворобу з симптомами: головний біль, нежить, кашель". Аналогічно, у випадку кінозйомки - користувач найчастіше набирає ім'я актора або режисера сам, шукаючи не його як людину, а фільми, в яких він брав участь. Особливості пошукового запиту - це не більше, ніж набір атрибутів у описі даного фільму, продукту тощо. Google прогнозує, яке таємне запитання запитує користувач, а потім намагається відповісти на нього. Загальний опис цього фактора ранжування Google можна знайти у запитанні: яка сутність (книга, фільм, продукт, хвороба, газета, транспортний засіб тощо) пов'язана з функціями, які відображаються в запиті користувача?
Приклад: однією з особливостей фільму є цитати. Тому, ввівши героя в пошуковий механізм, можна знайти назву фільму. За фразою: "Каргюль, приходьте на огорожу" Google прогнозує, що питання: "У якому фільмі вийшло питання про Каргюль, приходьте до огорожі". Цікаві приклади нижче, але ми рекомендуємо вам перевірити власні культові цитати з фільмів! Посилання на патент Google: Надання контексту результатів пошуку на основі пошукової фрази
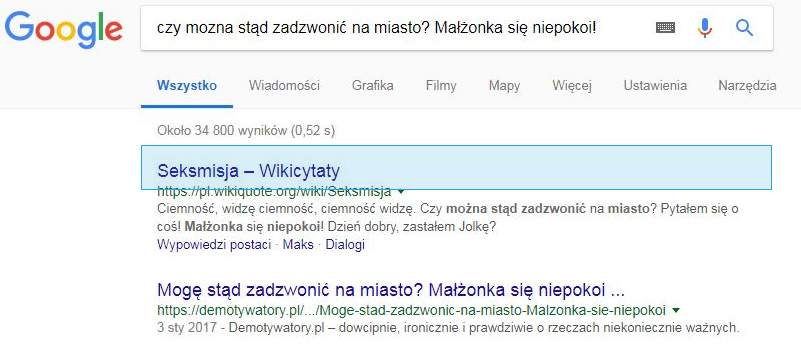
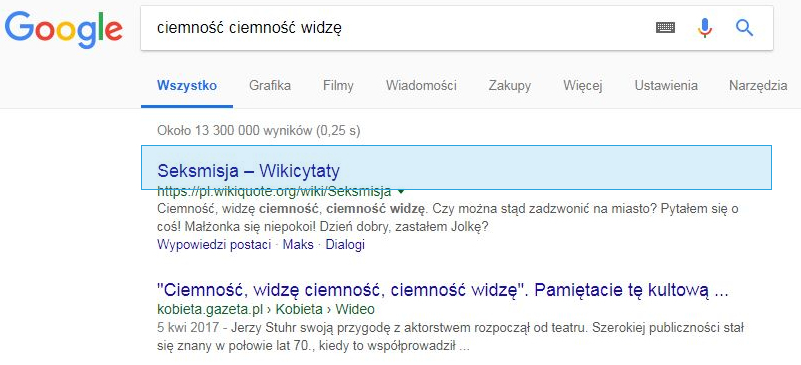

Рекомендації: Оскільки Google вміє читати характеристики суб'єкта та поєднувати їх із словами, введеними в пошукову систему, він належить до вмісту знизу вгору, написаного на його власному веб-сайті. З точки зору користувача, поставимо запитання: які характеристики користувачів, які шукають мої послуги або продукти? Повернемося до прикладу книжок - можливо, вони доглядають за автором: "книги Джейн Остін", після літературного жанру або епохи: "поезія античності" або, можливо, після персонажа: "Jakub Wędrowycz".
Результати пошуку та натуральна мова
Переглядаючи результати пошуку, ми бачимо фрагменти тексту цієї веб-сторінки у вигляді мета-опису. Google оцінив, що ці описи часто не дають надійної відповіді на запит користувача, а загальний опис підсторінки. Тому користувач повинен перейти на сторінку, прочитати фрагмент і шукати відповідь на своє питання. Мета-описи не є природними лінгвістичними результатами. Щоб покращити це, Google прагне надати природну мову в результатах пошуку: у вигляді списку, абзацу та фрагмента тексту всередині веб-сайту, так що користувач спочатку знаходить відповідь вже на сторінці результатів пошуку, а по-друге, переходить на веб-сайт після відповіді, але після розробки відповіді - якщо її цікавить. Посилання на патент Google: Природний стиль у результатах пошуку для запитів
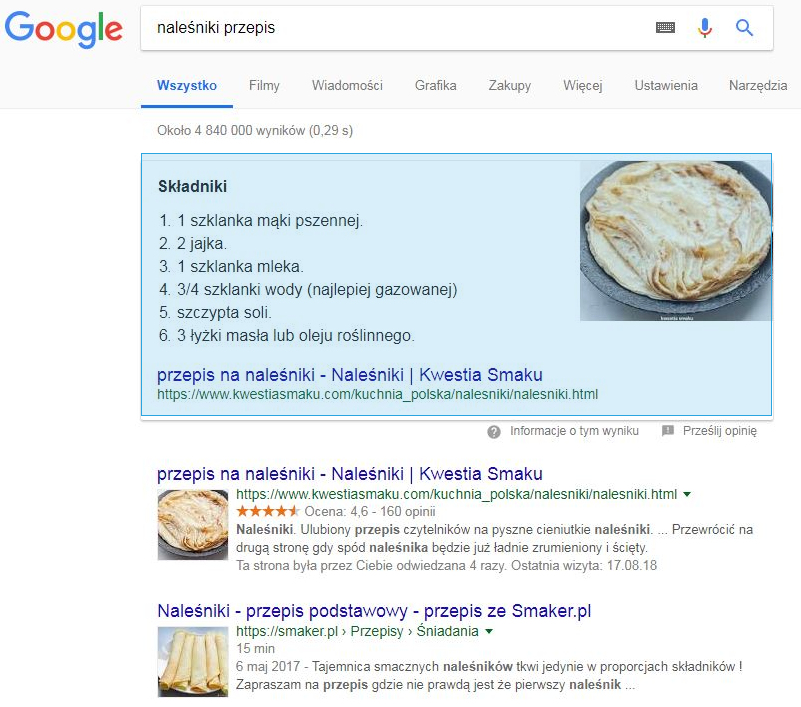
Рекомендації: поки що неможливо самостійно створити Графік знань із вмісту вашого власного веб-сайту, який може відображатися на певному запиті. Однак приклади графіків знань показують, що Google керує вмістом з чіткою структурою, як у прикладі нижче. Для запиту: "рецепт млинців" Google підказує Графік знань з інгредієнтами. Компоненти у вигляді точок, включених до веб-сайту, дозволили створити чіткий фрагмент, який вже відповідає користувачеві на рівні результатів пошуку.
Фактори ранжирування Google у контексті семантики - це мережа зв'язків між фразами та їх значеннями. Відмінна мережа - містить впорядковані дані, атрибути сутностей, з'єднань і локацій. Варто нагадати тут фільм, що представляє Google Knowledge Graph з шести років (!) Років тому, в якому вже розглянута концепція "інтелектуального побудови мережі зв'язків між даними". Асоціація з людським мозком і велика кількість нервових зв'язків, що впливають на інтелект - найбільш навмисне!
Фактори ранжирування Google, частина 7. Семантичні показники
5 (100%) 2 голосів
Приклад?
Чим відрізнятиметься цей патент від прохання поштового поста?
Приклади?
З точки зору користувача, поставимо запитання: які характеристики користувачів, які шукають мої послуги або продукти?
