

- Індексація сайту
- Чому так важливо управляти індексацією сайту
- Як можна заборонити індексацію окремих частин сайту і контенту?
- Robots.txt - директива user-agent і боти пошукових систем
- User-agent
- Назва роботів пошукових систем і їх роль у файлі robots.txt
- Приклади використання директив Disallow і Allow в роботс.тхт
- Директиви Sitemap і Host (для Яндекса) в Robots.txt
- Директива Host - вказує головне дзеркало сайту для Яндекса
- Вказуємо або приховуємо шлях до карти сайту sitemap.xml в файлі robots
- Перевірка robots.txt в Яндекс і Гугл вебмайстрів
- Причини помилок Виявлення при Перевірці файлу роботс.тхт
- Мета-тег Robots - допомагає закрити дублі контенту при індексації сайту
- Як створити правильний роботс.тхт?
- Robots для WordPress
- Правильний robots.txt для Joomla
при самостійному просуванні та розкрутці сайту важливо не тільки створення унікального контенту або підбір запитів в статистиці Яндекса , Але і так само слід приділяти належну увагу таким показником, як індексація ресурсу пошуковими системами, бо від цього теж залежить весь подальший успіх просування.
У нас з вами є в розпорядженні два набори інструментів, за допомогою яких ми можемо управляти цим процесом як би з двох сторін. По-перше, існує такий важливий інструмент як карта сайту ( Sitemap xml ). Вона каже пошуковим системам про те, які сторінки сайту підлягають індексації і як давно вони оновлювалися.
А, по-друге, це, звичайно ж, файл robots.txt і схожий на нього за назвою мета-тег Роботс, які допомагають нам заборонити індексування на сайті того, що не містить основного контенту (виключити файли движка, заборонити індексацію дублів контенту) , і саме про них і піде мова в цій статті ...
Індексація сайту
Згадані вище інструменти дуже важливі для успішного розвитку вашого проекту, і це зовсім не голослівне твердження. У статті про Sitemap xml (див. Посилання вище) я наводив у приклад результати дуже важливого дослідження по найбільш частим технічних помилок початківців вебмайстрів, там на другому і третьому місці (після того не унікального контенту) знаходяться якраз відсутність цих файлів Роботс і сайтмап, або їх неправильне складання і використання.
Чому так важливо управляти індексацією сайту
Треба дуже чітко розуміти, що при використанні CMS (движка) не всю інформацію сайту має бути доступне роботам пошукових систем. Чому?
- Ну, хоча б тому, що, витративши час на індексацію файлів движка вашого сайту (а їх може бути тисячі), робот пошукача до основного контенту зможе дістатися тільки через багато часу. Справа в тому, що він не буде сидіти на вашому ресурсі до тих пір, поки його повністю не занесе в індекс. Є ліміти на число сторінок і вичерпавши їх він піде на інший сайт. Адьес.
- Якщо не прописати певні правила поведінки в Роботс для цих ботів, то в індекс пошукових систем потрапить безліч сторінок, які не мають відношення до значимого вмісту ресурсу, а також може статися багаторазове дублювання контенту (за різними посиланнями буде доступний один і той же, або сильно перетинається контент ), що пошукові системи не люблять.
Хорошим рішенням буде заборона всього зайвого в robots.txt (всі букви в назві повинні бути в нижньому регістрі - без великих літер). З його допомогою ми зможемо впливати на процес індексації сайту Яндексом і Google. Представляє він з себе звичайний текстовий файл, який ви зможете створити і в подальшому редагувати в будь-якому текстовому редакторі (наприклад, Notepad ++).
Пошуковий робот буде шукати цей файл в кореневому каталозі вашого ресурсу і якщо не знайде, то буде заганяти в індекс все, до чого зможе дотягнутися. Тому після написання необхідного Роботс, його потрібно зберегти в кореневу папку, наприклад, за допомогою Ftp клієнта Filezilla так, щоб він був доступний наприклад за такою адресою:
https://ktonanovenkogo.ru/robots.txt
До речі, якщо ви хочете дізнатися як виглядає цей файл у того чи іншого проекту в мережі, то досить буде дописати до УРЛу його головної сторінки закінчення виду /robots.txt. Це може бути корисно для розуміння того, що в ньому має бути.
Однак, при цьому треба враховувати, що для різних движків цей файл буде виглядати по-різному (папки движка, які потрібно забороняти індексувати, будуть називатися по-різному в різних CMS). Тому, якщо ви хочете визначитися з найкращим варіантом Роботс, припустимо для вордпресс, то і вивчати потрібно тільки блоги, побудовані на цьому движку (і бажано мають пристойний пошуковий трафік).
Як можна заборонити індексацію окремих частин сайту і контенту?
Перш ніж заглиблюватися в деталі написання правильного файлу robots.txt для вашого сайту, забіжу трохи вперед і скажу, що це лише один із способів заборони індексації тих чи інших сторінок або розділів сайту. Взагалі їх три:
- Роботс.тхт - самий високорівнева спосіб, бо дозволяє задати правила індексації для всього сайту цілком (як його окремий сторінок, так і цілих каталогів). Він є повністю валідним методом, підтримуваним усіма пошуковими системами та іншими ботами живуть в мережі. Але його директиви зовсім не є обов'язковими для виконання. Наприклад, Гугл не дуже дивиться на заборони в robots.tx - для нього авторитетніше однойменний мета-тег розглянутий нижче.
- Мета-тег robots - має вплив тільки на сторінку, де він прописаний. У ньому можна заборонити індексацію і перехід робота по перебувають в цьому документі посиланнях (докладніше дивіться нижче). Він теж є повністю валідним і пошуковики будуть намагатися враховувати зазначені в ньому значення. Для Гугла, як я вже згадував, цей метод має більшу вагу, ніж файлик Роботс в корені сайту.
- Тег Noindex і атрибут rel = "nofollow" - самий низькорівневий спосіб впливу на індексацію. Вони дозволяють закрити від індексації окремі фрагменти тексту (noindex) і не враховувати вагу передається по посиланню. Вони не валідність (їх немає в стандартах). Як саме їх враховують пошуковики і враховують взагалі - велике питання і предмет довгих суперечок (хто знає напевно - той мовчить і користується).
Важливо розуміти, що навіть «стандарт» (валідність директиви robots.txt і однойменного мета-тега) є необов'язковим до виконання. Якщо робот «ввічливий», то він буде слідувати заданим вами правилами. Але навряд чи ви зможете за допомогою такого методу заборонити доступ до частини сайту роботам, які крадуть у вас контент або сканирующим сайт з інших причин.
Взагалі, роботів (ботів, павуків, краулерів) існує безліч. Якісь із них індексують контент (як наприклад, боти пошукових систем або злодюжок). Є боти перевіряючі посилання, поновлення, віддзеркалення, перевіряючі мікророзмітки і т.д. дивіться скільки роботів є тільки у Яндекса .
Більшість роботів добре спроектовані і не створюють будь-яких проблем для власників сайтів. Але якщо бот написаний дилетантом або «щось пішло не так», то він може створювати істотне навантаження на сайт, який він обходить. До речі, павуки зовсім на заходять на сервер подібно до вірусів - вони просто запитують потрібні їм сторінки віддалено (по суті це аналоги браузерів, але без функції перегляду сторінок).
Robots.txt - директива user-agent і боти пошукових систем
Роботс.тхт має зовсім не складний синтаксис, який дуже докладно описаний, наприклад, в хелпе яндекса і хелпе Гугла . Зазвичай в ньому вказується, для якого пошукового бота призначені описані нижче директиви: ім'я бота ( 'User-agent'), що дозволяють ( 'Allow') і забороняють ( 'Disallow'), а також ще активно використовується 'Sitemap' для вказівки пошуковим системам, де саме знаходиться файл карти.
Стандарт створювався досить давно і щось було додано вже пізніше. Є директиви і правила оформлення, які будуть зрозумілі тільки роботами певних пошукових систем. В рунеті інтерес представляють в основному тільки Яндекс і Гугл, а значить саме з їх Хелп по складанню robots.txt слід ознайомитися особливо детально (посилання я навів у попередньому абзаці).
Наприклад, раніше для пошукової системи Яндекс було корисним вказати, яке з дзеркал вашого вебпроектів є головним в спеціальній директиві 'Host', яку розуміє тільки цей пошуковик (ну, ще й Майл.ру, бо у них пошук від Яндекса). Правда, на початку 2018 Яндекс все ж скасував Host і тепер її функції як і у інших пошукачів виконує 301-редирект.
Якщо навіть у вашого ресурсу немає дзеркал, то корисно буде вказати, який з варіантів написання є головним - з www або без нього .
Тепер поговоримо трохи про синтаксис цього файлу. Директиви в robots.txt мають такий вигляд:
<Поле>: <пробіл> <значення> <пробіл> <поле>: <пробіл> <значення> <пробіл>
Правильний код повинен містити хоча б одну директиву «Disallow» після кожного запису «User-agent». Порожній файл передбачає дозвіл на індексування всього сайту.
User-agent
Директива «User-agent» повинна містити назву пошукового бота. За допомогою неї можна налаштувати правила поведінки для кожного конкретного пошукача (наприклад, створити заборона індексації окремої папки тільки для Яндекса). Приклад написання «User-agent», адресований усім роботам зайшли на ваш ресурс, виглядає так:
User-agent: *
Якщо ви хочете в «User-agent» задати певні умови тільки для якогось одного бота, наприклад, Яндекса, то потрібно написати так:
User-agent: Yandex
Назва роботів пошукових систем і їх роль у файлі robots.txt
Бот кожної пошукової системи має свою назву (наприклад, для Рамблера це StackRambler). Тут я приведу список найвідоміших з них:
Google http://www.google.com Googlebot Яндекс http://www.ya.ru Yandex Бінг http://www.bing.com/ bingbot
У великих пошукових систем іноді, крім основних ботів, є також окремі екземпляри для індексації блогів, новин, зображень і т.д. Багато інформації по різновидах ботів ви можете почерпнути тут (Для Яндекса) і тут (Для Google).
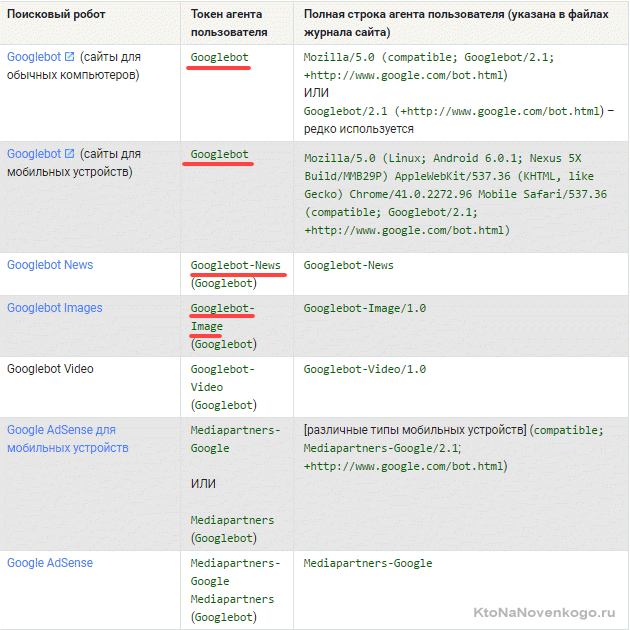
Як бути в цьому випадку? Якщо потрібно написати правило заборони індексації, яке повинні виконати всі типи роботів Гугла, то використовуйте назву Googlebot і всі інші павуки цього пошуковика теж послухають. Однак, можна заборона давати тільки, наприклад, на індексацію картинок, вказавши в якості User-agent бота Googlebot-Image. Зараз це не дуже зрозуміло, але на прикладах, я думаю, буде простіше.
Приклади використання директив Disallow і Allow в роботс.тхт
Наведу кілька простих прикладів використання директив з поясненням його дій.
- Наведений нижче код дозволяє всім роботам (на це вказує зірочка в User-agent) проводити індексацію всього вмісту без будь-яких винятків. Це задається порожній директивою Disallow. User-agent: * Disallow:
- Наступний код, навпаки, повністю забороняє всім пошуковим системам додавати в індекс сторінки цього ресурсу. Встановлює це Disallow з «/» в поле значення. User-agent: * Disallow: /
- У цьому випадку буде заборонятися всім роботам переглядати вміст каталогу / image / (http://mysite.ru/image/ - абсолютний шлях до цього каталогу) User-agent: * Disallow: / image /
- Щоб заблокувати один файл, досить буде прописати його абсолютний шлях до нього (читайте про абсолютні та відносні шляхи по посиланню ): User-agent: * Disallow: /katalog1//katalog2/private_file.html
Забігаючи трохи вперед скажу, що простіше використовувати символ зірочки (*), щоб не писати повний шлях:
Disallow: /*private_file.html
- У наведеному нижче прикладі будуть заборонені директорія «image», а також всі файли і директорії, що починаються з символів «image», т. Е. Файли: «image.htm», «images.htm», каталоги: «image», « images1 »,« image34 »і т. д.): User-agent: * Disallow: / image Справа в тому, що за замовчуванням в кінці запису мається на увазі зірочка, яка замінює будь-які символи, в тому числі і їх відсутність. Читайте про це нижче.
- За допомогою директиви Allow ми дозволяємо доступ. Добре доповнює Disallow. Наприклад, таким ось умовою пошуковому роботу Яндекса ми забороняємо викачувати (індексувати) всі, крім веб-сторінок, адреса яких починається з / cgi-bin: User-agent: Yandex Allow: / cgi-bin Disallow: /
Ну, або такий ось очевидний приклад використання зв'язки Allow і Disallow:
User-agent: * Disallow: / catalog Allow: / catalog / auto
- При описі шляхів для директив Allow-Disallow можна використовувати символи "*" та "$ ', задаючи, таким чином, певні логічні вирази.
- Символ '*' (зірочка) означає будь-яку (в тому числі порожню) послідовність символів. Наступний приклад забороняє всім пошуковим системам індексацію файлів з розширення «.php»: User-agent: * Disallow: * .php $
- Навіщо потрібен на кінці знак $ (долара)? Справа в тому, що за логікою складання файлу robots.txt, в кінці кожної директиви як би дописується умолчательную зірочка (її немає, але вона як би є). Наприклад ми пишемо: Disallow: / images
Маючи на увазі, що це те ж саме, що:
Disallow: / images *
Тобто це правило забороняє індексацію всіх файлів (веб-сторінок, картинок і інших типів файлів) адреса яких починається з / images, а далі слід все що завгодно (див. приклад вище). Так ось, символ $ просто скасовує цю умолчательную (непроставляемую) зірочку на кінці. наприклад:
Disallow: / images $
Забороняє тільки індексацію файлу / images, але не /images.html або /images/primer.html. Ну, а в першому прикладі ми заборонили індексацію тільки файлів закінчуються на .php (мають таке розширення), щоб нічого зайвого не зачепити:
Disallow: * .php $
Зірочка після знаку питання напрошується, але вона, як ми з вами з'ясували трохи вище, вже мається на увазі на кінці. Таким чином ми заборонимо індексацію сторінок пошуку і інших службових сторінок створюваних двигуном, до яких може дотягнутися пошуковий робот. Зайвим не буде, бо знак питання найчастіше CMS використовують як ідентифікатор сеансу, що може призводити до потрапляння в індекс дублів сторінок.
Директиви Sitemap і Host (для Яндекса) в Robots.txt
Для уникнення виникнення неприємних проблем з дзеркалами сайту, раніше рекомендувалося додавати в robots.txt директиву Host, яка вказував боту Yandex на головне дзеркало.
Однак, на початку 2018 року це було скасовано і і тепер функції Host виконує 301-редирект .
Директива Host - вказує головне дзеркало сайту для Яндекса
Наприклад, раніше, якщо ви ще не перейшли на захищений протокол, вказувати в Host потрібно було не повний Урл, а доменне ім'я (без http: //, тобто ktonanovenkogo.ru, а не https://ktonanovenkogo.ru) . Якщо ж вже перейшли на https, то вказувати потрібно буде повний Урл (типу https://myhost.ru).
зараз переїзд сайту після відмови від директиви Host дуже сильно спростився, бо тепер не потрібно чекати поки відбудеться склейка дзеркал за директивою Host для Яндекса, а можна відразу після завершення налаштування Https на сайті робити посторінковий редирект з Http на Https.
Нагадаю як історичного екскурсу, що за стандартом написання роботс.тхт за будь директивою User-agent повинна відразу слідувати хоча б одна директива Disallow (нехай навіть і порожня, нічого не забороняє). Так само, напевно, є сенс прописувати Host для окремого блоку «User-agent: Yandex», а не для загального «User-agent: *», щоб не збивати з пантелику роботів інших пошукачів, які цю директиву не підтримують:
User-agent: Yandex Disallow: Host: www.site.ru
або
User-agent: Yandex Disallow: Host: site.ru
або
User-agent: Yandex Disallow: Host: https://site.ru
або
User-agent: Yandex Disallow: Host: https://www.site.ru
в залежності від того, що для вас оптимальніше (з www або без), а так само в залежності від протоколу.
Вказуємо або приховуємо шлях до карти сайту sitemap.xml в файлі robots
Директива Sitemap вказує на місце розташування файлу карти сайту (зазвичай він називається Sitemap.xml, але не завжди). Як параметр вказується шлях до цього файлу, включаючи http: // (тобто його Урл) .Завдяки цьому пошуковий робот зможете без праці його знайти. наприклад:
Sitemap: http://site.ru/sitemap.xml
Раніше файл карти сайту зберігали в корені сайту, але зараз багато його ховають всередині інших директорій, щоб злодіям контенту не давати зручний інструмент в руки. В цьому випадку шлях до карти сайту краще в роботс.тхт не вказувати. Справа в тому, що це можна з тим же успіхом зробити через панелі пошукових систем ( Я.Вебмастер , Google.Вебмастер , панель Майл.ру ), Тим самим «Не палячи» його місцезнаходження.
Місцезнаходження директиви Sitemap у файлі robots.txt не регламентується, бо вона не зобов'язана ставитися до якогось юзер-агенту. Зазвичай її прописують в самому кінці, або взагалі не прописують з наведених вище причин.
Перевірка robots.txt в Яндекс і Гугл вебмайстрів
Як я вже згадував, різні пошукові системи деякі директиви можуть интерпритировать по різному. Тому має сенс перевіряти написаний вами файл роботс.тхт в панелях для вебмайстрів обох систем. Як перевіряти?
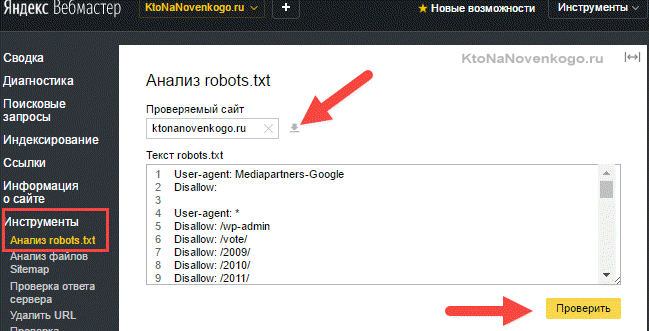
- Зайти в інструменти перевірки Яндекса і Гугла .
- Переконатися, що в панель вебмастера завантажена версія файлу з внесеними вами змінами. В Яндекс вебмайстрів завантажити змінений файл можна за допомогою показаної на скріншоті іконки:
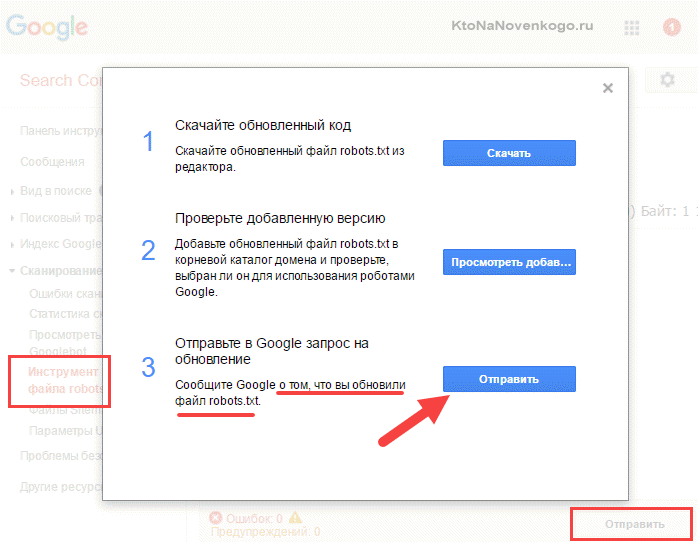
В Гугл вебмайстрів потрібно натиснути кнопку «Відправити» (праворуч під списком директив Роботс), а потім у вікні, вибрати останній варіант натисканням знову ж на кнопку «Відправити»:
- Набрати список адрес сторінок свого сайту (по УРЛу в рядку), які повинні індексуватися, і вставити їх скопом (в Яндексі) або по одному (в Гуглі) в розташовану знизу форму. Після чого натиснути на кнопку «Перевірити».
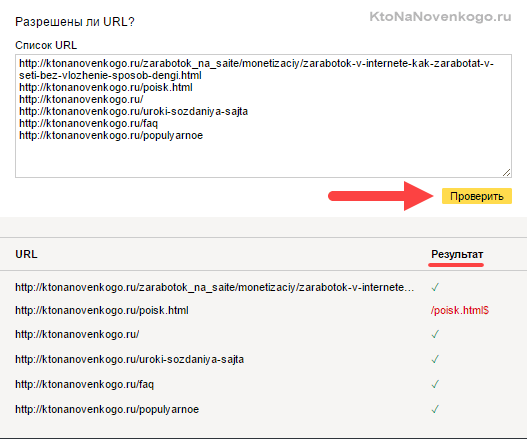
Якщо виникли нестиковки, то з'ясувати причини, внести зміни в robots.txt, завантажити оновлений файл в панель вебмайстрів і повторити перевірку. Все ОК?
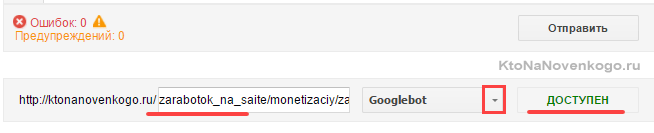
Тоді Складанний список сторінок, Які НЕ повінні індексуватіся, и проводите їх перевірку. При необхідності вносите Зміни и перевірку повторюйте. Природно, что перевіряті слід НЕ Всі сторінки сайту, а яскраве представителей свого класу (Сторінки статей, рубрики, службові Сторінки, файли картинок, файли шаблону, файли движка и т.д.)
Причини помилок Виявлення при Перевірці файлу роботс.тхт
- Файл повинен знаходітіся в корені сайту, а не в якійсь папці (Це не .htaccess, и его Дії пошірюються на весь сайт, а не на каталог, в якому его помістілі), бо пошуковий робот его там шукати НЕ буде.
- Назва и Розширення файлу robots.txt винне буті набрано в нижньому регістрі (маленькими) Латинська літерами.
- У назві файлу винна буті буква S на кінці (Не robot.txt, як много пишуть)
- Часто в User-agent замість зірочки (означає, що цей блок robots.txt адресований усім роботам) залишають порожнє поле. Це не правильно і * в цьому випадку обов'язкова User-agent: * Disallow: /
- В одній директиві Disallow або Allow можна прописувати тільки одна умова на заборону індексації директорії або файлу. Так не можна: Disallow: / feed / / tag / / trackback /
Для кожного умови потрібно додати своє Disallow:
Disallow: / feed / Disallow: / tag / Disallow: / trackback /
- Досить часто плутають значення для директив і пишуть: User-agent: / Disallow: Yandex
вместо
User-agent: Yandex Disallow: /
- Порядок проходження Disallow (Allow) не важливий - головне, щоб була чітка логічна ланцюг
- Порожня директива Disallow означає те ж, що «Allow: /»
- Немає сенсу прописувати директиву sitemap під кожним User-agent, якщо будете вказувати шлях до карти сайту (читайте про це нижче), то робіть це один раз, наприклад, в самому кінці.
- Директиву Host краще писати під окремим «User-agent: Yandex», щоб не бентежити ботів її не підтримує
Мета-тег Robots - допомагає закрити дублі контенту при індексації сайту
Існує ще один спосіб налаштувати (дозволити або заборонити) індексацію окремих сторінок сайту, як для Яндекса, так і для Гугл. Причому для Google цей метод набагато пріоритетнішою описаного вище. Тому, якщо потрібно напевно закрити сторінку від індексації цією пошуковою системою, то даний мета-тег потрібно буде прописувати в обов'язковому порядку.
Для цього всередині тега «HEAD» потрібної вебсторінки дописується МЕТА-тег Robots з потрібними параметрами, і так повторюється для всіх документів, до яких потрібно застосувати ту чи іншу правило (заборона або дозвіл). Виглядати це може, наприклад, так:
<Html> <head> <meta name = "robots" content = "noindex, nofollow"> <meta name = "description" content = "Ця сторінка ...."> <title> ... </ title> < / head> <body> ...
В цьому випадку, боти всіх пошукових систем повинні будуть забути про індексацію цієї вебсторінки (про це говорить присутність noindex в даному мета-тезі) і аналізі розміщених на ній посилань (про це говорить присутність nofollow - боту забороняється переходити за посиланнями, які він знайде в цьому документі).
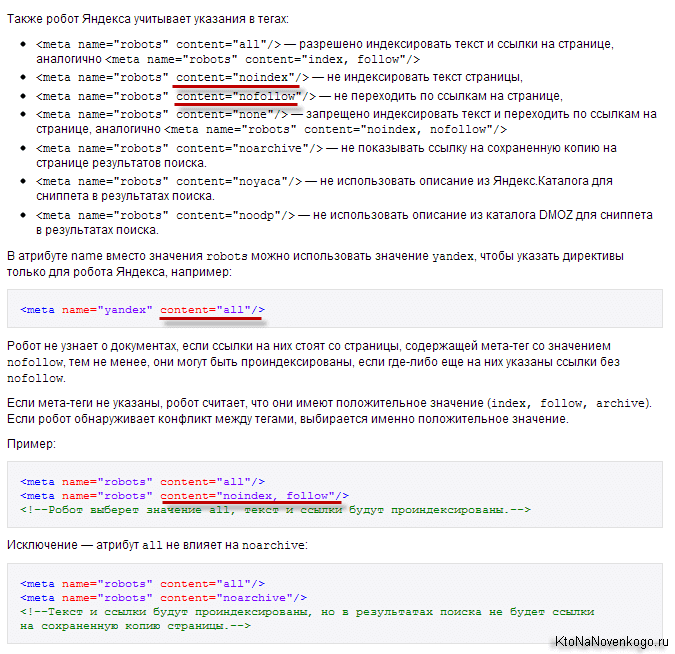
Існують тільки дві пари параметрів у метатега robots: [no] index і [no] follow:
- Index - вказують, чи може робот проводити індексацію даного документа
- Follow - чи може він йти по посиланнях, знайденим в цьому документі
Значення за замовчуванням (коли цей мета-тег для сторінки взагалі не прописаний) - «index» і «follow». Є також укорочений варіант написання з використанням «all» і «none», які позначають активність обох параметрів або, відповідно, навпаки: all = index, follow і none = noindex, nofollow.
Більш докладні пояснення можна знайти, наприклад, в хелпе Яндекса:
Для блогу на WordPress ви зможете налаштувати мета-тег Robots, наприклад, за допомогою плагіна All in One SEO Pack . Якщо використовуєте інші плагіни або інші движки сайту, то гуглити на тему прописування для потрібних сторінок meta name = "robots".
Як створити правильний роботс.тхт?
Ну все, з теорією покінчено і пора переходити до практики, а саме до складання оптимальних robots.txt. Як відомо, у проектів, створених на основі будь-якого движка (Joomla, WordPress та ін), є безліч допоміжних об'єктів не несуть ніякої інформативної навантаження.
Якщо не заборонити індексацію всього цього сміття, то час, відведений пошуковими системами на індексацію вашого сайту, буде витрачатися на перебір файлів движка (на предмет пошуку в них інформаційної складової, тобто контенту). Але фішка в тому, що в більшості CMS контент зберігається не в файлик, а в базі даних, до якої пошуковим роботам ніяк не добратися. Полазити по сміттєвих об'єктів движка, бот вичерпає відпущений йому час і піде піймавши облизня.
Крім того, слід прагнути до унікальності контенту на своєму проекті і не слід допускати повного або навіть часткового дублювання контенту (інформаційного вмісту). Дублювання може виникнути в тому випадку, якщо один і той же матеріал буде доступний за різними адресами (URL).
Яндекс і Гугл, проводячи індексацію, виявлять дублі і, можливо, вживуть заходів до деякої пессимізації вашого ресурсу при їх великій кількості (машинні ресурси коштують дорого, а тому витрати потрібно мінімізувати). Так, є ще така штука, як мета-тег Canonical .
Чудовий інструмент для боротьби з дублями контенту - пошуковик просто не буде індексувати сторінку, якщо в Canonical прописаний інший урл. Наприклад, для такої сторінки https://ktonanovenkogo.ru/page/2 мого блогу (сторінки з пагінацією) Canonical вказує на https://ktonanovenkogo.ru і ніяких проблем з дублюванням тайтлів виникнути не повинно.
<Link rel = "canonical" href = "https://ktonanovenkogo.ru/" />
Але це я відволікся ...
Якщо ваш проект створений на основі будь-якого движка, то дублювання контенту матиме місце з високою ймовірністю, а значить потрібно з ним боротися, в тому числі і за допомогою заборони в robots.txt, а особливо в мета-тезі, бо в першому випадку Google заборона може і проігнорувати, а ось на метатег наплювати він вже не зможе (так вихований).
Наприклад, в WordPress сторінки з дуже схожим вмістом можуть потрапити в індекс пошукових систем, якщо дозволена індексація і вмісту рубрик, і вмісту архіву тегів, і вмісту тимчасових архівів. Але якщо за допомогою описаного вище мета-тега Robots створити заборона для архіву тегів і тимчасового архіву (можна теги залишити, а заборонити індексацію вмісту рубрик), то дублювання контенту не виникне. Як це зробити описано за посиланням наведеної трохи вище (на плагін ОлІнСеоПак)
Підводячи підсумок скажу, що файл Роботс призначений для налаштування загальних правил заборони доступу в цілі директорії сайту, або в файли і папки, в назві яких присутні задані символи (по масці). Приклади завдання таких заборон ви можете подивитися трохи вище.
Тепер давайте розглянемо конкретні приклади Роботс, призначеного для різних движків - Joomla, WordPress і SMF. Природно, що всі три варіанти, створені для різних CMS, будуть істотно (якщо не сказати кардинально) відрізнятися один від одного. Правда, у всіх у них буде один загальний момент, і момент цей пов'язаний з пошуковою системою Яндекс.
Оскількі в рунеті Яндекс має досить велику вагу, то потрібно враховувати всі нюанси його роботи, і тут нам допоможе директива Host. Вона в явній формі вкаже цього пошуковику головне дзеркало вашого сайту.
Для неї радять використовувати окремий блог User-agent, призначений тільки для Яндекса (User-agent: Yandex). Це пов'язано з тим, що інші пошукові системи можуть не розуміти Host і, відповідно, її включення в запис User-agent, призначену для всіх пошукових систем (User-agent: *), може призвести до негативних наслідків і неправильної індексації.
Як йде справа насправді - сказати важко, бо алгоритми роботи пошуку - це річ в собі, тому краще зробити так, як радять. Але в цьому випадку доведеться продублювати в директиві User-agent: Yandex все ті правила, що ми задали User-agent: *. Якщо ви залишите User-agent: Yandex з порожнім Disallow :, то таким чином ви дозволите Яндексу заходити куди завгодно і тягнути все підряд в індекс.
Robots для WordPress
Не буду наводити приклад файлу, який рекомендують розробники. Ви і самі можете його подивитися. Багато блогерів взагалі не обмежують ботів Яндекса і Гугла в їх прогулянках по вмісту движка WordPress. Найчастіше в блогах можна зустріти Роботс, автоматично заповнений плагіном Google XML Sitemaps .
Але, по-моєму, все-таки слід допомогти пошуку в нелегкій справі відсіювання зерен від плевел. По-перше, на індексацію цього сміття піде багато часу у ботів Яндекса і Гугла, і може зовсім не залишитися часу для додавання в індекс веб-сторінок з вашими новими статтями. По-друге, боти, що лазять по сміттєвих файлів движка, будуть створювати додаткове навантаження на сервер вашого хоста, що не є добре.
Мій варіант цього файлу ви можете самі подивитися. Він старий, давно не змінювався, але я намагаюся дотримуватися принципу «не чини те, що не ламалося», а вам вже вирішувати: використовувати його, зробити свій або ще у когось підглянути. У мене там ще заборона індексації сторінок з пагінацією був прописаний до недавнього часу (Disallow: * / page /), але недавно я його прибрав, сподіватимемося на Canonical, про який писав вище.
А взагалі, єдино правильного файлу для WordPress, напевно, не існує. Можна, звичайно ж, реалізувати в ньому будь-які передумови, але хто сказав, що вони будуть правильними. Варіантів ідеальних robots.txt в мережі багато.
Наведу дві крайності:
- тут можна знайти мегафайліще з докладними поясненнями (символом # відокремлюються коментарі, які в реальному файлі краще буде видалити): User-agent: * # загальні правила для роботів, крім Яндекса і Google, # тому для них правила нижче Disallow: / cgi-bin # папка на хостингу Disallow: /? # Всі параметри запиту на головній Disallow: / wp- # всі файли WP: / wp-json /, / wp-includes, / wp-content / plugins Disallow: / wp / # якщо є підкаталог / wp /, де встановлена CMS ( якщо немає, # правило можна видалити) Disallow: *? s = # пошук Disallow: * & s = # пошук Disallow: / search / # пошук Disallow: / author / # архів автора Disallow: / users / # архів авторів Disallow: * / trackback # трекбеки, повідомлення в коментарях про появу відкритої # посилання на статтю Disallow: * / feed # все фіди Disallow: * / rss # rss фід Disallow: * / embed # все вбудовування Disallow: * / wlwmanifest.xml # xml-файл маніфесту Windows Live Writer (якщо не використовуєте, # правило можна видалити) Disallow: /xmlrpc.php # файл WordPress API Disallow: * utm = # сси ки з utm-мітками Disallow: * openstat = # посилання з мітками openstat Allow: * / uploads # відкриваємо папку з файлами uploads User-agent: GoogleBot # правила для Google (коментарів не дублюю) Disallow: / cgi-bin Disallow: /? Disallow: / wp- Disallow: / wp / Disallow: *? S = Disallow: * & s = Disallow: / search / Disallow: / author / Disallow: / users / Disallow: * / trackback Disallow: * / feed Disallow: * / rss Disallow: * / embed Disallow: * / wlwmanifest.xml Disallow: /xmlrpc.php Disallow: * utm = Disallow: * openstat = Allow: * / uploads Allow: /*/*.js # відкриваємо js-скрипти всередині / wp - (/ * / - для пріоритету) Allow: /*/*.css # відкриваємо css-файли всередині / wp- (/ * / - для пріоритету) Allow: /wp-*.png # картинки в плагінах, cache папці і т.д. Allow: /wp-*.jpg # картинки в плагінах, cache папці і т.д. Allow: /wp-*.jpeg # картинки в плагінах, cache папці і т.д. Allow: /wp-*.gif # картинки в плагінах, cache папці і т.д. Allow: /wp-admin/admin-ajax.php # використовується плагінами, щоб не блокувати JS і CSS User-agent: Yandex # правила для Яндекса (коментарів не дублюю) Disallow: / cgi-bin Disallow: /? Disallow: / wp- Disallow: / wp / Disallow: *? S = Disallow: * & s = Disallow: / search / Disallow: / author / Disallow: / users / Disallow: * / trackback Disallow: * / feed Disallow: * / rss Disallow: * / embed Disallow: * / wlwmanifest.xml Disallow: /xmlrpc.php Allow: * / uploads Allow: /*/*.js Allow: /*/*.css Allow: /wp-*.png Allow: /wp-*.jpg Allow: /wp-*.jpeg Allow: /wp-*.gif Allow: /wp-admin/admin-ajax.php Clean-Param: utm_source & utm_medium & utm_campaign # Яндекс рекомендує не закривати # від індексування, а видаляти параметри міток, # Google такі правила не підтримує Clean-Param: openstat # аналогічно # Вкажіть один або декілька файлів Sitemap (дублювати для кожного User-agent # не потрібно). Google XML Sitemap створює 2 карти сайту, як в прикладі нижче. Sitemap: http://site.ru/sitemap.xml Sitemap: http://site.ru/sitemap.xml.gz # Вкажіть головне дзеркало сайту, як в прикладі нижче (з WWW / без WWW, якщо HTTPS # то пишемо протокол, якщо потрібно вказати порт, вказуємо). Команду Host розуміє # Яндекс і Mail.RU, Google не враховує. Host: www.site.ru
- А от тут можна взяти на озброєння приклад мінімалізму: User-agent: * Disallow: / wp-admin / Allow: /wp-admin/admin-ajax.php Host: https://site.ru Sitemap: https://site.ru/ sitemap.xml
Істина, напевно, лежить десь посередині. Ще не забудьте прописати мета-тег Robots для «зайвих» сторінок, наприклад, за допомогою чудесного плагіна - All in One SEO Pack . Він же допоможе і Canonical налаштувати.
Правильний robots.txt для Joomla
Рекомендований файл для Джумли 3 виглядає так (живе він у файлі robots.txt.dist кореневої папки движка):
User-agent: * Disallow: / administrator / Disallow: / bin / Disallow: / cache / Disallow: / cli / Disallow: / components / Disallow: / includes / Disallow: / installation / Disallow: / language / Disallow: / layouts / Disallow: / libraries / Disallow: / logs / Disallow: / modules / Disallow: / plugins / Disallow: / tmp /
В принципі, тут практично все враховано і працює він добре. Єдине, в нього слід додати окреме правило User-agent: Yandex для вставки директиви Host, що визначає головне дзеркало для Яндекса, а так само вказати шлях до файлу Sitemap.
Тому в остаточному вигляді правильний robots для Joomla, на мою думку, має виглядати так:
User-agent: Yandex Disallow: / administrator / Disallow: / cache / Disallow: / includes / Disallow: / installation / Disallow: / language / Disallow: / libraries / Disallow: / modules / Disallow: / plugins / Disallow: / tmp / Disallow: / layouts / Disallow: / cli / Disallow: / bin / Disallow: / logs / Disallow: / components / Disallow: / component / Disallow: / component / tags * Disallow: / * mailto / Disallow: /*.pdf Disallow : / *% Disallow: /index.php Host: vash_sait.ru (або www.vash_sait.ru) User-agent: * Allow: /*.css?*$ Allow: /*.js?*$ Allow: / * .jpg? * $ Allow: /*.png?*$ Disallow: / administrator / Disallow: / cache / Disallow: / includes / Disallow: / installation / Disallow: / language / Disallow: / libraries / Disallow: / modules / Disallow : / plugins / Disallow: / tmp / Disallow: / layouts / Disallow: / cli / Disallow: / bin / Disallow: / logs / Disallow: / components / Disallow: / component / Disallow: / * mailto / Disallow: / *. pdf Disallow: / *% Disallow: /index.php Sitemap: http: // шлях до вашої карті XML формату
Так, ще зверніть увагу, що в другому варіанті є директиви Allow, що дозволяють індексацію стилів, скриптів і картинок. Написано це спеціально для Гугла, бо його Googlebot іноді лається, що в Роботс заборонена індексація цих файлів, наприклад, з папки з використовуваної темою оформлення. Навіть погрожує за це знижувати в ранжируванні.
Тому заздалегідь все це справа дозволяємо індексувати за допомогою Allow. Те ж саме, до речі, і в прикладі файлу для Вордпресс було.
Удачі вам! До швидких зустрічей на страницах блогу KtoNaNovenkogo.ru
Збірки по темі
Використову для заробітку
Чому?Як можна заборонити індексацію окремих частин сайту і контенту?
Як бути в цьому випадку?
Txt: User-agent: * Disallow: / *?
Як перевіряти?
Все ОК?
Disallow: / wp- Disallow: / wp / Disallow: *?
Php # використовується плагінами, щоб не блокувати JS і CSS User-agent: Yandex # правила для Яндекса (коментарів не дублюю) Disallow: / cgi-bin Disallow: /?
